Linking Methods
Figure 1 shows a comparison of different linking methods according to their type I and type II errors.
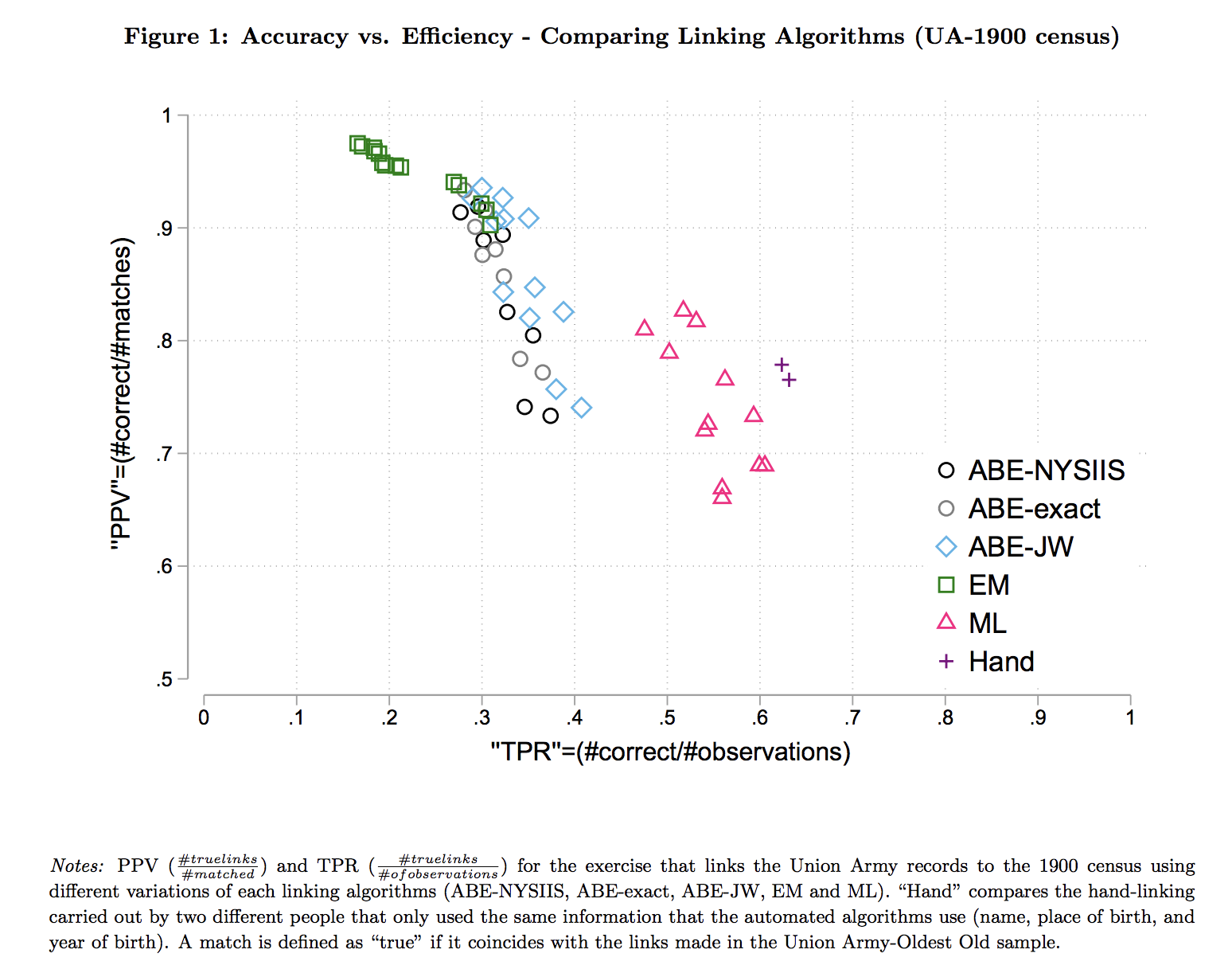
This figure refers to a series of linking methods currently used or soon to be added to this project (e.g., the ABE method, machine learning method, and EM method). Details of these linking methods can be found in the paper “Automated Linking of Historical Data” by Ran Abramitzky, Leah Platt Boustan, Katherine Eriksson, James J. Feigenbaum, and Santiago Pérez. The crosswalks also include links shared by collaborators (Joseph Price, Kasey Buckles, Jacob Van Leewen and Isaac Riley, 2019)
Each method involves a tradeoff between the number of matches made and the accuracy of the matches (TPR vs PPV). Methods with a lower PPV create more mis-matches. Mis-matches arise due to challenges such as transcription and enumeration errors, mortality1, under-enumeration, common names and international migration between census years. The figure also documents that mis-matches occur in linked datasets created by human linkers. Because the weight placed on sample size versus accuracy may differ based on the research question, we urge users to familiarize themselves with the methods and select the linking algorithm that best fits with their research design.
The linking methods also vary in their ability to link different populations. For example, women are hard to match because they often change surname at marriage and so we only provide links for men on the site. African Americans and some immigrant groups have lower match rates than white, US-born men. Small samples of foreign born populations with transcription errors will be prone to higher false positive rates. Researchers should use links for such samples with caution and rely on their judgement to determine which linking method is best for their context.
A set of codes and documentation that can be used to implement each of these methods can be downloaded from our data page or found at this website. These codes are also available as a GitHub repository (ABE and EM) and ICPSR repository
1 Missed links due to mortality will be a larger problem when linking between two Censuses conducted a number of years apart (i.e. matching from the 1850 Census to 1940 Census) and so links created over a long time span should be used with caution.